هجا یک واحد سازماندهی برای دنباله ای از صداهای گفتاری است که معمولاً از یک هسته هجا (اغلب یک مصوت ) با حاشیه های ابتدایی و پایانی اختیاری (معمولاً همخوان ها ) تشکیل شده است. هجاها اغلب به عنوان "بلوک های سازنده" واجی کلمات در نظر گرفته می شوند . [1] آنها می توانند بر ریتم یک زبان، عروض آن ، متر شعر و الگوهای استرس آن تأثیر بگذارند . گفتار را معمولاً میتوان به تعدادی هجا تقسیم کرد: برای مثال، کلمه ignite از دو هجا ساخته شده است: ig و nite .
نوشتن هجایی چند صد سال قبل از اولین حروف شروع شد . قدیمی ترین هجاهای ثبت شده بر روی الواح نوشته شده در حدود 2800 قبل از میلاد در شهر سومری اور است . این تغییر از پیکتوگرام به هجا «مهمترین پیشرفت در تاریخ نگارش » نامیده شده است. [2]
کلمه ای که از یک هجا تشکیل شده باشد (مانند سگ انگلیسی ) تک هجا نامیده می شود (و به آن تک هجا گفته می شود ). اصطلاحات مشابه شامل بی هجایی (و بی هجایی ؛ همچنین دو هجایی و دو هجایی ) برای یک کلمه دو هجایی است. سه هجا (و سه هجا ) برای یک کلمه سه هجا. و چند هجا (و چند هجا )، که ممکن است به کلمه ای بیش از سه هجا یا هر کلمه ای بیش از یک هجا اشاره داشته باشد.
هجا یک تغییر انگلیسی-نرمنی از sillabe فرانسوی قدیم است ، از syllaba لاتین ، از یونانی Koine συλλαβή syllabḗ ( تلفظ یونانی: [sylːabɛ̌ː] ). συλλαβή به معنای "با هم گرفته شده" است، به حروفی که با هم گرفته می شوند تا یک صدای واحد ایجاد کنند. [3]
συλλαβή یک اسم فعل از فعل συλλαμβάνω syllambánō ، ترکیبی از حرف اضافه σύν sýn "با" و فعل λαμβάνω lambánō "گرفتن" است. [4] اسم از ریشه λαβ- استفاده می کند که در زمان آئوریست ظاهر می شود . ساقه زمان حال λαμβάν- با اضافه کردن یک پسوند بینی ⟨ μ ⟩ ⟨m⟩ قبل از β b و پسوند -αν -an درانتهای آن تشکیل می شود. [5]
در الفبای آوایی بین المللی (IPA)، نقطه پایانی ⟨ . ⟩ شکست های هجا را نشان می دهد، همانطور که در کلمه "نجومی" ⟨ /ˌæs.trə.ˈnɒm.ɪk.əl/ ⟩.
با این حال، در عمل، رونویسی IPA معمولاً به کلمات بر اساس فاصله تقسیم میشود، و اغلب این فاصلهها به صورت شکسته شدن هجا نیز شناخته میشوند. علاوه بر این، علامت تاکیدی ⟨ ˈ ⟩ بلافاصله قبل از هجای تاکید شده قرار می گیرد و زمانی که هجای تاکید شده در وسط یک کلمه قرار می گیرد، در عمل علامت تاکیدی نیز شکست هجا را نشان می دهد، مثلا در کلمه "فهمیده" ⟨ /ʌndərˈstʊd/ ⟩ (اگرچه ممکن است مرز هجا همچنان به صراحت با نقطه نقطه مشخص شود، [6] به عنوان مثال ⟨ /ʌn.dər.ˈstʊd/ ⟩).
هنگامی که یک فاصله کلمه در وسط یک هجا قرار می گیرد (یعنی زمانی که یک هجا کلمات را در بر می گیرد)، مانند ترکیب فرانسوی les amis ⟨ /lɛ.z‿a.mi می توان از نوار کراوات ⟨ ‿ ⟩ برای ارتباط استفاده کرد . / ⟩. پیوند رابط همچنین برای الحاق کلمات واژگانی به کلمات واجی ، به عنوان مثال هات داگ ⟨ /ˈhɒt‿dɒɡ/ ⟩ استفاده می شود.
یک سیگمای یونانی، ⟨σ⟩ ، به عنوان کارت وحشی برای "هجا" استفاده می شود ، و یک علامت دلار/پسو، ⟨$⟩ ، مرز هجا را مشخص می کند که در آن نقطه معمولی ممکن است اشتباه درک شود. برای مثال، ⟨σσ⟩ یک جفت هجا است، و ⟨V$⟩ یک مصوت هجا-پایانی است.


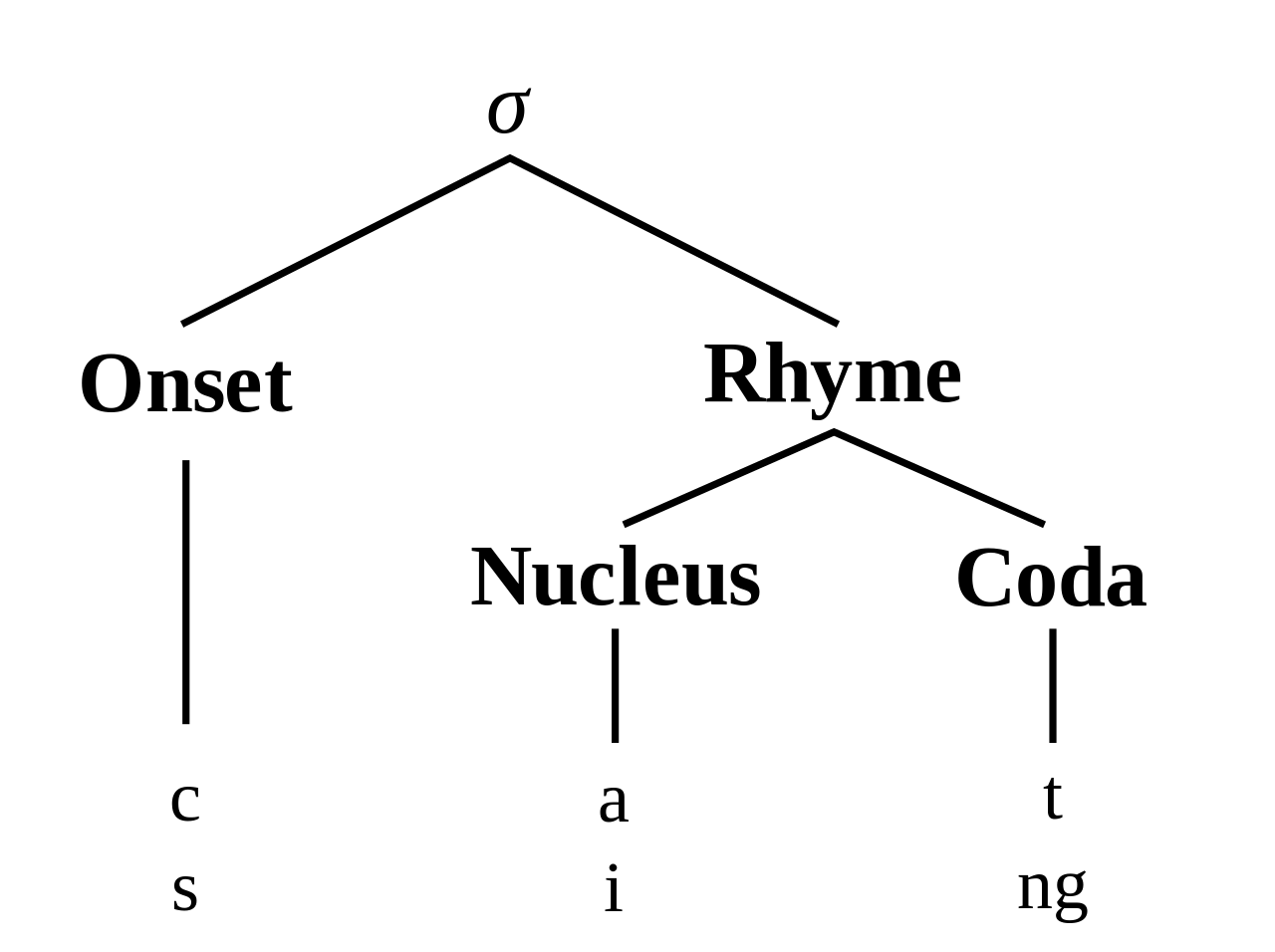
در نظریه معمولی [ نیازمند منبع ] ساختار هجا، ساختار کلی یک هجا (σ) از سه بخش تشکیل شده است. این بخش ها به دو بخش تقسیم می شوند:
هجا معمولاً شاخه راست در نظر گرفته می شود، یعنی هسته و کدا با هم به عنوان "ریم" گروه بندی می شوند و فقط در سطح دوم متمایز می شوند.
هسته معمولا مصوت در وسط هجا است . شروع صدا یا صداهایی است که قبل از هسته رخ می دهد و کودا ( به معنای واقعی کلمه "دم") صدا یا صداهایی است که به دنبال هسته می آیند. آنها گاهی اوقات به طور جمعی به عنوان پوسته شناخته می شوند . اصطلاح رایم شامل هسته به اضافه کدا می شود. در واژه انگلیسی تک هجای cat ، هسته a (صدایی که می تواند به تنهایی فریاد بزند یا خوانده شود)، شروع c ، coda t و ریم در است . این هجا را می توان به صورت یک هجای همخوان - مصوت - صامت ، به اختصار CVC انتزاع کرد . زبانها در محدودیتهای مربوط به صداهایی که شروع، هسته و کد یک هجا را تشکیل میدهند، با توجه به آنچه آوا تاکتیک زبان نامیده میشود، بسیار متفاوت هستند .
اگرچه هر هجا دارای ویژگیهای فرابخشی است، اما اگر از نظر معنایی مرتبط نباشند، معمولاً نادیده گرفته میشوند، مثلاً در زبانهای آهنگی .

در ساختار هجای زبانهای سینیتی ، شروع با یک حرف اول جایگزین میشود و یک نیمه مصوت یا مایع بخش دیگری را تشکیل میدهد که به آن میانی میگویند. این چهار بخش به دو جزء کمی متفاوت گروه بندی می شوند: [ نمونه مورد نیاز ]
در بسیاری از زبانهای منطقه زبانشناختی آسیای جنوب شرقی ، مانند چینی ، ساختار هجا به گونهای گسترش مییابد که بخش میانی اختیاری و اضافی را در بر میگیرد که بین آغاز (اغلب در این زمینه، ابتدایی نامیده میشود ) و ریم. میانی معمولاً یک نیمه مصوت است ، اما بازسازیهای چینی قدیم عموماً شامل میانیهای مایع میشوند ( /r/ در بازسازیهای مدرن، /l/ در نسخههای قدیمی)، و بسیاری از بازسازیهای چینی میانه شامل تضاد میانی بین /i/ و /j/ میشوند. ، جایی که /i/ از نظر واج شناختی به عنوان یک سر خوردن عمل می کند نه به عنوان بخشی از هسته. علاوه بر این، بسیاری از بازسازیهای چینی قدیم و میانه شامل رسانههای پیچیده مانند /rj/ ، /ji/ ، /jw/ و /jwi/ است . میانی از نظر واج شناسی با لبه به جای شروع گروه بندی می شود و ترکیب میانی و ریم در مجموع به عنوان نهایی شناخته می شود .
برخی از زبان شناسان، به ویژه هنگام بحث در مورد انواع مدرن چینی، از اصطلاحات "پایانی" و "ریم" به جای یکدیگر استفاده می کنند. با این حال، در واجشناسی تاریخی چینی ، تمایز بین «نهایی» (از جمله میانی) و «ریم» (بدون احتساب میانی) در درک فرهنگهای لغت و جداول حاشیهای که منابع اولیه چینی میانه را تشکیل میدهند، مهم است . در نتیجه اکثر نویسندگان این دو را با توجه به تعریف فوق متمایز می کنند.

در برخی از نظریه های واج شناسی، ساختارهای هجا به صورت نمودار درختی نمایش داده می شوند (مشابه درختانی که در برخی از انواع نحو یافت می شوند). همه واج شناسان موافق نیستند که هجاها ساختار درونی دارند. در واقع، برخی از واج شناسان در وجود هجا به عنوان یک موجود نظری تردید دارند. [9]
استدلال های زیادی برای رابطه سلسله مراتبی، به جای رابطه خطی، بین اجزای تشکیل دهنده هجا وجود دارد. یک مدل سلسله مراتبی هسته هجا و کدا را در یک سطح متوسط، یعنی ریم گروه بندی می کند . مدل سلسله مراتبی نقشی را که ترکیب هسته + کدا در شعر ایفا می کند (یعنی کلمات قافیه مانند گربه و خفاش از تطبیق هسته و کودا یا کل ریم تشکیل می شوند) و برای تمایز بین سنگین و سبک توضیح می دهد. هجاها ، که در فرآیندهای آوایی مانند، برای مثال، تغییر صدا در انگلیسی قدیم scipu و wordu نقش دارند ، که در فرآیندی به نام حذف مصوت بالا (HVD)، جمع اسمی/اشاره ای ریشه های تک هجای سبک (مانند " *scip-") یک "u" دارد که به OE ختم می شود، در حالی که ریشه های هجای سنگین (مانند "*word-") این کار را نمی کنند و "scip-u" اما "word-∅" را می دهند. [10] [11] [12]

در برخی از توصیفهای سنتی زبانهای خاص مانند کری و اوجیبوه ، هجا بهعنوان شاخه چپ، یعنی گروه شروع و هسته زیر یک واحد سطح بالاتر، به نام «بدن» یا «هسته» در نظر گرفته میشود. این با کدا در تضاد است.
ریم یا قافیه یک هجا از یک هسته و یک کد اختیاری تشکیل شده است . این بخشی از هجا است که در بیشتر قافیه های شعری استفاده می شود ، و بخشی است که زمانی که شخص در گفتار کلمه ای را دراز می کند یا تأکید می کند، طولانی یا تأکید می شود.
ریم معمولاً بخشی از یک هجا از مصوت اول تا آخر است. به عنوان مثال، /æt/ دور تمام کلمات در , sat و flat است . با این حال، هسته لزوماً نیازی به واکه در برخی از زبان ها مانند انگلیسی ندارد. به عنوان مثال، لبه هجای دوم کلمات بطری و کمانچه فقط /l/ است که یک صامت مایع است .
همانطور که ریم به هسته و کدا منشعب می شود، هسته و کدا نیز ممکن است هر کدام به چند واج منشعب شوند . محدودیت برای تعداد واج هایی که ممکن است در هر کدام وجود داشته باشد برحسب زبان متفاوت است. به عنوان مثال، زبان ژاپنی و اکثر زبان های چینی- تبتی در ابتدا یا انتهای هجاها خوشه های همخوان ندارند، در حالی که بسیاری از زبان های اروپای شرقی می توانند بیش از دو صامت در ابتدا یا انتهای هجا داشته باشند. در زبان انگلیسی، شروع ممکن است تا سه صامت داشته باشد و کدا چهار. [13]
ریم و قافیه انواعی از یک کلمه هستند، اما شکل نادرتر ریم گاهی به معنای لبه هجای خاص استفاده می شود تا آن را از مفهوم قافیه شاعرانه متمایز کند . این تمایز توسط برخی از زبان شناسان صورت نگرفته و در اکثر لغت نامه ها آمده است.

هجای سنگین عموماً هجایی است که لبه انشعاب دارد ، یعنی یا هجای بسته ای است که به صامت ختم می شود، یا هجای با هسته انشعاب ، یعنی مصوت بلند یا دوبله . این نام یک استعاره است که بر اساس هسته یا کدا دارای خطوطی است که در نمودار درختی منشعب می شوند.
در برخی از زبانها، هجاهای سنگین شامل هجاهای VV (هسته شاخهدار) و VC (ریم شاخهدار) میشوند، در مقابل V، که یک هجای سبک است . در زبان های دیگر، تنها هجاهای VV سنگین در نظر گرفته می شوند، در حالی که هر دو هجای VC و V سبک هستند. برخی از زبان ها نوع سوم هجای فوق سنگین را متمایز می کنند که شامل هجاهای VVC (هم با هسته و هم هسته منشعب) یا هجاهای VCC (با یک کد متشکل از دو یا چند صامت) یا هر دو است.
در تئوری مورائیک ، هجاهای سنگین دارای دو مور و هجاهای سبک دارای یک و هجاهای فوق سنگین دارای سه هجا هستند. آواشناسی ژاپنی به طور کلی به این صورت توصیف می شود.
بسیاری از زبان ها هجاهای فوق سنگین را ممنوع می کنند، در حالی که تعداد قابل توجهی هر هجای سنگین را ممنوع می کنند. برخی از زبان ها برای وزن ثابت هجا تلاش می کنند. به عنوان مثال، در هجاهای تاکیدی و غیر پایانی در ایتالیایی ، مصوت های کوتاه با هجاهای بسته همراه هستند در حالی که مصوت های بلند با هجاهای باز همراه هستند، به طوری که همه این هجاها سنگین هستند (نه سبک یا فوق سنگین).
تفاوت بین سنگین و سبک اغلب تعیین می کند که کدام هجاها استرس دارند - برای مثال در لاتین و عربی این مورد وجود دارد . سیستم متر شاعرانه در بسیاری از زبان های کلاسیک، مانند یونانی کلاسیک ، لاتین کلاسیک ، تامیل قدیم و سانسکریت ، به جای تاکید بر وزن هجا (به اصطلاح ریتم کمی یا متر کمی ) استوار است.
هجایی عبارت است از تفکیک یک کلمه به هجاها، اعم از گفتاری یا نوشتاری. در بیشتر زبانها، هجاهایی که واقعاً گفته میشود، اساس هجاسازی در نوشتار نیز هستند. به دلیل تطابق بسیار ضعیف بین صداها و حروف در املای انگلیسی مدرن، برای مثال، هجای نوشتاری در زبان انگلیسی باید بیشتر بر اساس ریشهشناسی یعنی صرفشناختی به جای اصول آوایی باشد. بنابراین هجاهای نوشتاری انگلیسی با هجاهای واقعی زبان زنده مطابقت ندارند.
قوانین فونوتاکتیک تعیین می کند که کدام صداها در هر قسمت از هجا مجاز یا غیر مجاز هستند. انگلیسی اجازه هجاهای بسیار پیچیده را می دهد. هجاها ممکن است با حداکثر سه حرف بی صدا شروع شوند (مثل قدرت )، و گهگاه با چهار همخوان پایان می یابند [14] (مانند angsts ، تلفظ [æŋsts]). بسیاری از زبان های دیگر بسیار محدودتر هستند. برای مثال، زبان ژاپنی فقط به /ɴ/ و کرونیم در کدا اجازه می دهد، و از نظر تئوری اصلاً خوشه همخوانی ندارد، زیرا شروع حداکثر از یک صامت تشکیل شده است. [15]
پیوند یک صامت آخر کلمه به مصوتی که بلافاصله بعد از آن کلمه شروع می شود، بخش منظمی از آوایی برخی از زبان ها از جمله اسپانیایی، مجارستانی و ترکی را تشکیل می دهد. بنابراین، در زبان اسپانیایی، عبارت los hombres ("مردان") [loˈsom.bɾes] ، مجارستانی az ember ("انسان") به صورت [ɒˈzɛm.bɛr] و ترکی nefret ettim ("من از آن متنفر بودم" تلفظ می شود. به عنوان [nefˈɾe.tet.tim] . در ایتالیایی، صدای [j] پایانی را میتوان به هجای بعدی منتقل کرد، گاهی اوقات با دوجنس: به عنوان مثال، non ne ho mai avuti («من هرگز هیچ یک از آنها را نداشتهام») به هجاهای [non] تقسیم میشود. .neˈɔ.ma.jaˈvuːti] و io ci vado e lei anche («من به آنجا می روم و او نیز انجام می دهد») به صورت [jo.tʃiˈvaːdo.e.lɛjˈjaŋ.ke] تحقق می یابد . یک پدیده مرتبط، به نام جهش همخوان، در زبانهای سلتی مانند ایرلندی و ولزی یافت میشود که به موجب آن صامتهای پایانی نانوشته (اما تاریخی) بر همخوان اولیه کلمه زیر تأثیر میگذارند.
ممکن است در مورد محل برخی از تقسیمات بین هجاها در زبان گفتاری اختلاف نظر وجود داشته باشد. مشکلات برخورد با چنین مواردی بیشتر در رابطه با زبان انگلیسی مورد بحث قرار گرفته است. در مورد کلمهای مانند عجله ، تقسیم ممکن است /hʌr.i/ یا /hʌ.ri/ باشد ، که هیچ کدام برای لهجهای غیرروتیک مانند RP (انگلیسی انگلیسی): /hʌr تحلیل رضایتبخشی به نظر نمیرسد. i/ منجر به یک هجای آخر /r/ میشود که معمولاً یافت نمیشود، در حالی که /hʌ.ri/ یک واکه تاکیدی کوتاه پایانی هجا را میدهد که آن هم غیرواقعی است. استدلالهایی میتوان به نفع یک راهحل یا راهحل دیگر ارائه کرد: یک قاعده کلی پیشنهاد شده است که میگوید «با توجه به شرایط معین...، صامتها با تأکید شدیدتر دو هجای کناری هجا میشوند» [16] در حالی که بسیاری از آنها سایر واج شناسان ترجیح می دهند تا حد امکان هجاها را با صامت یا صامت های متصل به هجای زیر تقسیم کنند. با این حال، جایگزینی که تا حدودی مورد حمایت قرار گرفته است این است که یک صامت بینواکاسی را بهعنوان دو هجا تلقی کنیم ، یعنی هم به هجای قبلی و هم به هجای زیر تعلق دارد: /hʌṛi/ . این موضوع در آواشناسی انگلیسی § Phonotactics با جزئیات بیشتر مورد بحث قرار گرفته است .
شروع (همچنین به عنوان آنلاوت شناخته می شود ) صدای همخوان یا صداهای ابتدای هجا است که قبل از هسته رخ می دهد . بیشتر هجاها شروعی دارند. هجاهای بدون شروع ممکن است گفته شود که شروعی خالی یا صفر دارند - یعنی هیچ شروعی در آن وجود ندارد.
برخی از زبانها شروع را محدود میکنند که فقط یک صامت باشد، در حالی که برخی دیگر بر اساس قوانین مختلف شروع چند صامتی را مجاز میدانند. به عنوان مثال، در زبان انگلیسی، شروع هایی مانند pr- ، pl- و tr- ممکن است اما tl- نیست، و sk- ممکن است اما ks- نیست. با این حال، در یونانی ، هر دو ks- و tl- شروع ممکن هستند، در حالی که برعکس در عربی کلاسیک هیچ شروع چند صامتی اصلا مجاز نیست.
برخی از زبان ها شروع پوچ را ممنوع می کنند . در این زبان ها، کلماتی که با یک مصوت شروع می شوند، مانند کلمه انگلیسی at ، غیرممکن است.
این کمتر از آن چیزی است که ممکن است در ابتدا به نظر برسد، زیرا اغلب این زبانها به هجاها اجازه میدهند که با یک توقف گلوتال واجی شروع شوند (صدا در وسط انگلیسی uh-oh یا در برخی از گویشها، دکمه T دوتایی در نشان داده شده در IPA به صورت /ʔ/ ). در زبان انگلیسی، کلمهای که با یک مصوت شروع میشود، ممکن است هنگام مکث با یک توقف گلوتال اپنتتیک تلفظ شود، اگرچه ممکن است توقف گلوتال یک واج در زبان نباشد .
تعداد کمی از زبانها بین کلمهای که با یک مصوت شروع میشود و کلمهای که با توقف گلوتال و سپس یک مصوت شروع میشود تمایز واجی قائل میشوند، زیرا این تمایز معمولاً فقط پس از یک کلمه دیگر قابل شنیدن است. با این حال، مالتی و برخی از زبان های پلینزی چنین تمایزی قائل می شوند، مانند در هاوایی /ahi/ ('آتش') و /ʔahi / ← /kahi/ ('tuna') و مالتی /∅/ ← عربی /h/ و مالتی / k~ʔ/ ← عربی /ق/ .
عبری اشکنازی و سفاردی معمولاً ممکن است א ، ה و ע را نادیده بگیرند و عربی شروع های خالی را ممنوع می کند. اسامی اسرائیل ، هابیل ، ابراهیم ، عمر ، عبدالله و عراق ظاهراً در هجای اول شروع نمیشوند، اما در شکلهای اصلی عبری و عربی در واقع با صامتهای مختلف شروع میشوند: نیمواکه / j / در יִשְׂרָאֵל yisra'él . اصطکاکی گلوتال در / h / הֶבֶל heḇel ، توقف گلوتال / ʔ / در אַבְרָהָם ' aḇrāhām ، یا اصطکاک حلق / ʕ / در عُمَدُل ʿلَم . و عِرَاق عراق . در مقابل، زبان Arrernte در استرالیای مرکزی ممکن است شروع را به طور کامل ممنوع کند. اگر چنین است، تمام هجاها شکل زیرین VC(C) دارند. [17]
تفاوت بین یک هجا با شروع صفر و یک هجا که با یک توقف گلوتال شروع می شود، اغلب صرفاً یک تفاوت در تحلیل واج شناختی است ، نه تلفظ واقعی هجا. در برخی موارد، تلفظ یک کلمه واکه اولیه (به طور فرضی) هنگام دنبال کردن یک کلمه دیگر - به ویژه اینکه آیا یک نقطه گلوتال درج شده باشد یا نه - نشان می دهد که آیا کلمه باید شروعی پوچ در نظر گرفته شود یا خیر. به عنوان مثال، بسیاری از زبانهای عاشقانه مانند اسپانیایی هرگز چنین توقفی را درج نمیکنند، در حالی که انگلیسی فقط در برخی مواقع این کار را انجام میدهد، بسته به عواملی مانند سرعت مکالمه. در هر دو مورد، این نشان می دهد که کلمات مورد نظر واقعاً مصوت اولیه هستند.
اما در اینجا استثناهایی نیز وجود دارد. به عنوان مثال، آلمانی استاندارد (به استثنای بسیاری از لهجههای جنوبی) و عربی هر دو مستلزم این هستند که بین یک کلمه و یک کلمه پس از آن، که ظاهراً مصوت اولیه است، یک نقطه قلاب درج شود. با این حال تصور می شود که چنین کلماتی با یک مصوت در آلمانی شروع می شوند، اما در زبان عربی با یک توقف زبانی. دلیل این امر به ویژگی های دیگر این دو زبان مربوط می شود. به عنوان مثال، توقف گلوتال در موقعیتهای دیگر در آلمانی رخ نمیدهد، به عنوان مثال قبل از یک صامت یا در انتهای کلمه. از سوی دیگر، در عربی، نه تنها در چنین موقعیتهایی توقف گلوتال اتفاق میافتد (مثلاً کلاسیک /saʔala/ «پرسید»، /raʔj/ «نظر»، /dˤawʔ/ «نور»)، بلکه در تناوبهایی رخ میدهد که به وضوح نشان دهنده وضعیت آوایی آن هستند (ر.ک. کلاسیک /kaːtib/ «نویسنده» در مقابل /mak tuːb/ «نوشته شده»، /ʔaːkil/ «خورنده» در مقابل /maʔkuːl/ «خورده»). به عبارت دیگر، در حالی که توقف گلوتال در آلمانی قابل پیشبینی است (تنها در صورتی درج میشود که هجای تاکیدی با یک مصوت شروع شود)، [18] همان صدا یک واج همخوان منظم در عربی است. وضعیت این صامت در سیستم های نوشتاری مربوطه با این تفاوت مطابقت دارد: در املای آلمانی هیچ بازتابی از توقف گلوتال وجود ندارد ، اما یک حرف در الفبای عربی وجود دارد ( حمزه (ء)).
سیستم نوشتاری یک زبان ممکن است با تحلیل واجشناختی زبان از نظر مدیریت (بالقوه) شروعهای پوچ مطابقت نداشته باشد. به عنوان مثال، در برخی از زبانهایی که با الفبای لاتین نوشته شدهاند ، یک نقطه اولیه گلوتال نانوشته باقی میماند (به مثال آلمانی مراجعه کنید). از سوی دیگر، برخی از زبانهایی که با الفبای غیر لاتین نوشته میشوند، مانند ابجد و ابوگیدا، صامت صفر خاصی دارند که نشاندهنده شروع پوچ است. به عنوان مثال، در هانگول ، الفبای زبان کره ای ، یک شروع تهی با ㅇ در سمت چپ یا بالای یک گرافم نشان داده می شود ، مانند 역 "ایستگاه"، تلفظ شده yeok ، که در آن دوفتانگ yeo هسته و k است. کدا است.

هسته معمولا مصوت در وسط هجا است . به طور کلی، هر هجا به یک هسته نیاز دارد (گاهی اوقات اوج نامیده می شود )، و هجای حداقلی فقط از یک هسته تشکیل شده است، همانطور که در کلمات انگلیسی "eye" یا "owe" وجود دارد. هسته هجا معمولاً مصوت است و به صورت تکفثنگ ، دوگانه یا سهتنگ است، اما گاهی اوقات صامت هجایی است .
در بیشتر زبانهای آلمانی ، حروف صدادار ضعیف فقط در هجاهای بسته وجود دارند. بنابراین، به این مصوت ها، مصوت های علامت دار نیز گفته می شود ، برخلاف مصوت های زمانی که به آنها واکه آزاد می گویند ، زیرا می توانند حتی در هجاهای باز نیز وجود داشته باشند.
مفهوم هجا توسط زبانهایی به چالش کشیده میشود که اجازه میدهند رشتههای طولانی مانع بدون هیچ مصوت یا صدادار میانی وجود داشته باشد . تا حد زیادی متداولترین همخوانهای هجایی صداهایی مانند [l] ، [r] ، [m] ، [n] یا [ŋ] هستند ، مانند انگلیسی bott le ، ch ur ch (در لهجههای روتیک)، ریتم m ، لب به لب. و کلید قفل کن . با این حال، انگلیسی به موانع هجایی در چند جملات مربوط به جملات فراکلامی مانند shh (برای فرمان سکوت) و psst (برای جلب توجه استفاده میشود) اجازه میدهد. همه اینها به صورت هجای واجی تحلیل شده اند. هجاهای فقط انسدادی نیز از نظر آوایی در برخی موقعیتهای عروضی، زمانی که مصوتهای بدون تاکید بین هجاها جابجا میشوند، دیده میشوند، مانند سیبزمینی [pʰˈteɪɾəʊ] و امروز [tʰˈdeɪ] که با وجود از دست دادن یک هسته هجا، تعداد هجاهایشان تغییر نمیکند.
تعداد کمی از زبانها در سطح واجی دارای اصطلاحات هجایی هستند که به عنوان مصوتهای اصطکاکی نیز شناخته میشوند . (در زمینه آواشناسی چینی ، معمولاً از اصطلاح مرتبط اما غیر مترادف واکه آپیکال استفاده می شود.) چینی ماندارین به دلیل داشتن چنین صداهایی حداقل در برخی از گویش هایش مشهور است، به عنوان مثال هجاهای پینیین si shi ri که معمولاً تلفظ می شود [. sź̩ ʂʐ̩́ ʐʐ̩́] به ترتیب. اگرچه، مانند هسته کلیسای روتیک انگلیسی ، بحث بر سر این است که آیا این هسته ها صامت هستند یا مصوت.
زبانهای سواحل شمال غربی آمریکای شمالی، از جمله زبانهای سالیشان ، واکاشان و چینوکان ، حتی در دقیقترین تلفظ ، همخوانهای توقفی و اصطکاکیهای بیصدا را به عنوان هجا در سطح واجی مجاز میکنند. به عنوان مثال چینوک [ɬtʰpʰt͡ʃʰkʰtʰ] "آن دو زن از این راه از آب بیرون می آیند". زبان شناسان این وضعیت را به طرق مختلف تحلیل کرده اند، برخی استدلال می کنند که چنین هجاهایی اصلا هسته ندارند و برخی معتقدند که مفهوم "هجا" را نمی توان به وضوح در مورد این زبان ها به کار برد.
نمونه های دیگر:
در بررسی باگمیهل از تحلیلهای قبلی، او متوجه میشود که کلمه بلا کولا /t͡sʼktskʷt͡sʼ/ «او رسید» بسته به تحلیلی که استفاده میشود به 0، 2، 3، 5 یا 6 هجا تجزیه میشود. یک تحلیل تمام بخشهای مصوت و صامت را به عنوان هستههای هجا در نظر میگیرد، تحلیلی دیگر تنها یک زیرمجموعه کوچک ( اصطکاکی یا همخوانی ) را بهعنوان نامزد هسته در نظر میگیرد و دیگری به سادگی وجود هجاها را کاملاً انکار میکند. با این حال، هنگام کار با ضبطها به جای رونویسی، هجاها میتوانند در چنین زبانهایی واضح باشند و گویشوران بومی شهود قوی نسبت به چیستی هجاها دارند.
این نوع پدیده همچنین در زبانهای بربر (مانند ایندلاون تاشلهیت بربر )، زبانهای مون-خمر (مانند سمای ، تمیار ، خمو ) و گویش اوگامی میاکو ، یک زبان ریوکیوایی، گزارش شده است . [20]
کدا (همچنین به عنوان auslaut شناخته می شود ) شامل صداهای همخوان یک هجا است که از هسته پیروی می کند. توالی هسته و کدا را ریم می گویند. برخی از هجاها فقط از یک هسته، فقط یک شروع و یک هسته بدون کدا، یا فقط یک هسته و کدا بدون شروع تشکیل شده اند.
فونوتاکتیک بسیاری از زبان ها کدهای هجا را ممنوع می کند . به عنوان مثال سواحیلی و هاوایی هستند . در برخی دیگر، کداها محدود به زیرمجموعه کوچکی از صامت هایی هستند که در موقعیت شروع ظاهر می شوند. به عنوان مثال، در سطح واجی در ژاپنی ، یک کدا ممکن است فقط یک نازال (هموارگانیک با هر صامت زیر) یا، در وسط یک کلمه، تلفیقی از صامت زیر باشد. (در سطح آوایی، کدهای دیگر به دلیل حذف /i/ و /u/ رخ می دهند.) در زبان های دیگر، تقریباً هر صامتی که به عنوان شروع مجاز باشد در کدا نیز مجاز است، حتی خوشه هایی از همخوان ها . به عنوان مثال، در زبان انگلیسی، همه صامت های شروع به جز /h/ به عنوان کدهای هجا مجاز هستند.
اگر کدا از یک خوشه همخوان تشکیل شده باشد، صدا معمولاً از اول به آخر کاهش می یابد، مانند کلمه انگلیسی help . این سلسله مراتب صدا (یا مقیاس صدا) نامیده می شود. [24] بنابراین خوشه های شروع انگلیسی و کدا متفاوت هستند. شروع /str/ در نقاط قوت به عنوان کدا در هیچ کلمه انگلیسی ظاهر نمی شود. با این حال، برخی از خوشه ها هم به عنوان شروع و هم به عنوان کدا رخ می دهند، مانند /st/ در stardust . سلسله مراتب صدا در برخی از زبان ها سختگیرانه تر و در برخی دیگر سختگیرانه تر است.
هجای بدون کد به شکل V، CV، CCV و غیره (V = مصوت، C = صامت) هجای باز یا هجای آزاد نامیده می شود ، در حالی که هجای دارای کد (VC، CVC، CVCC و غیره) است. ) هجای بسته یا هجای چک شده نامیده می شود . آنها هیچ ربطی به مصوت های باز و بسته ندارند ، بلکه بر اساس واجی که هجا را به پایان می رساند تعریف می شوند: یک مصوت (هجای باز) یا یک صامت (هجای بسته). تقریباً همه زبان ها هجاهای باز را مجاز می دانند، اما برخی مانند هاوایی هجاهای بسته ندارند.
هنگامی که یک هجا آخرین هجا در یک کلمه نیست، هسته معمولا باید با دو صامت دنبال شود تا هجا بسته شود. این به این دلیل است که یک همخوان منفرد زیر به طور معمول شروع هجای زیر در نظر گرفته می شود. برای مثال، casar اسپانیایی ("ازدواج کردن") از یک هجای باز و به دنبال آن یک هجای بسته ( ca-sar ) تشکیل شده است، در حالی که cansar "خسته شدن" از دو هجای بسته ( can-sar ) تشکیل شده است. هنگامی که یک صامت جثه ای (دوگانه) رخ می دهد، مرز هجا در وسط قرار می گیرد، به عنوان مثال "کرم" پانا ایتالیایی ( pan-na ); رجوع کنید به پنه ایتالیایی "نان" ( pa-ne ).
کلمات انگلیسی ممکن است از یک هجای بسته تشکیل شده باشند که هسته آن با ν و کدا با κ نشان داده می شود:
کلمات انگلیسی همچنین ممکن است از یک هجای باز منفرد تشکیل شده باشد که به یک هسته ختم می شود، بدون کد:
فهرستی از نمونههای کداهای هجای انگلیسی در فونولوژی انگلیسی#Coda یافت میشود .
برخی از زبان ها، مانند هاوایی ، کدا را ممنوع می کنند، به طوری که همه هجاها باز هستند.
دامنه ویژگی های فرابخشی یک هجا (یا برخی واحدهای بزرگتر) است، اما نه یک صدای خاص. به این معنا که این ویژگیها ممکن است بیش از یک بخش و احتمالاً همه بخشهای یک هجا را تحت تأثیر قرار دهند:
گاهی اوقات طول هجا نیز به عنوان یک ویژگی فرابخشی به حساب می آید. برای مثال، در برخی از زبانهای ژرمنی، مصوتهای بلند ممکن است فقط با صامتهای کوتاه وجود داشته باشند و بالعکس. با این حال، هجاها را می توان به عنوان ترکیبی از واج های بلند و کوتاه تجزیه و تحلیل کرد، مانند فنلاندی و ژاپنی، که در آن همخوانی و طول مصوت مستقل هستند.
در بیشتر زبانها، زیر و بمی یا کانتوری که در آن یک هجا تلفظ میشود، سایههایی از معنی مانند تأکید یا شگفتی را منتقل میکند یا یک عبارت را از یک سؤال متمایز میکند. با این حال، در زبانهای لحنی، گام بر معنای واژگانی اصلی (مثلاً «گربه» در مقابل «سگ») یا معنای دستوری (مانند گذشته در مقابل حال) تأثیر میگذارد. در برخی از زبانها، فقط خود زیر و بم (مثلاً بالا در مقابل پایین) این تأثیر را دارد، در حالی که در برخی دیگر، بهویژه زبانهای آسیای شرقی مانند چینی ، تایلندی یا ویتنامی ، شکل یا کانتور (مثلاً سطح در مقابل افزایش در مقابل سقوط) نیز وجود دارد. باید متمایز شود
ساختار هجا اغلب با استرس یا لهجه زیرین تعامل دارد. به عنوان مثال، در لاتین ، تنش به طور منظم با وزن هجا تعیین می شود ، اگر حداقل یکی از موارد زیر را داشته باشد، هجا به عنوان سنگین به حساب می آید:
در هر مورد، هجا دارای دو مور در نظر گرفته می شود .
هجای اول کلمه، هجای ابتدایی و هجای آخر، هجای پایانی است .
در زبانهایی که بر یکی از سه هجای آخر تأکید میکنند، هجای آخر را ultima ، هجای بعدی تا آخر را penult و سومین هجای آخر را پیشقدم میگویند. این اصطلاحات از لاتین ultima "آخر"، paenultima "تقریبا آخرین" و antepaenultima "قبل از تقریبا آخرین" آمده اند.
در یونان باستان ، سه علامت لهجه وجود دارد (حاد، دور، و قبر)، و اصطلاحات برای توصیف کلمات بر اساس موقعیت و نوع لهجه استفاده میشدند. برخی از این اصطلاحات در توصیف زبان های دیگر استفاده می شود.
گیلهم مولینیر ، یکی از اعضای کنسیستوری دل گی سابر ، که اولین آکادمی ادبی در جهان بود و بازی های گل را برگزار کرد تا به بهترین تروبادور جایزه برتر violeta d'aur اهدا شود، در Leys d خود تعریفی از هجا ارائه کرد. Amor (1328-1337)، کتابی با هدف تنظیم شعر اکسیتان که در آن زمان شکوفا شده بود :